
以图灵机为师:通过微调训练让大语言模型懂执行计算过程
以图灵机为师:通过微调训练让大语言模型懂执行计算过程大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。
来自主题: AI技术研报
5658 点击 2024-10-18 13:54
 搜索
搜索
大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。
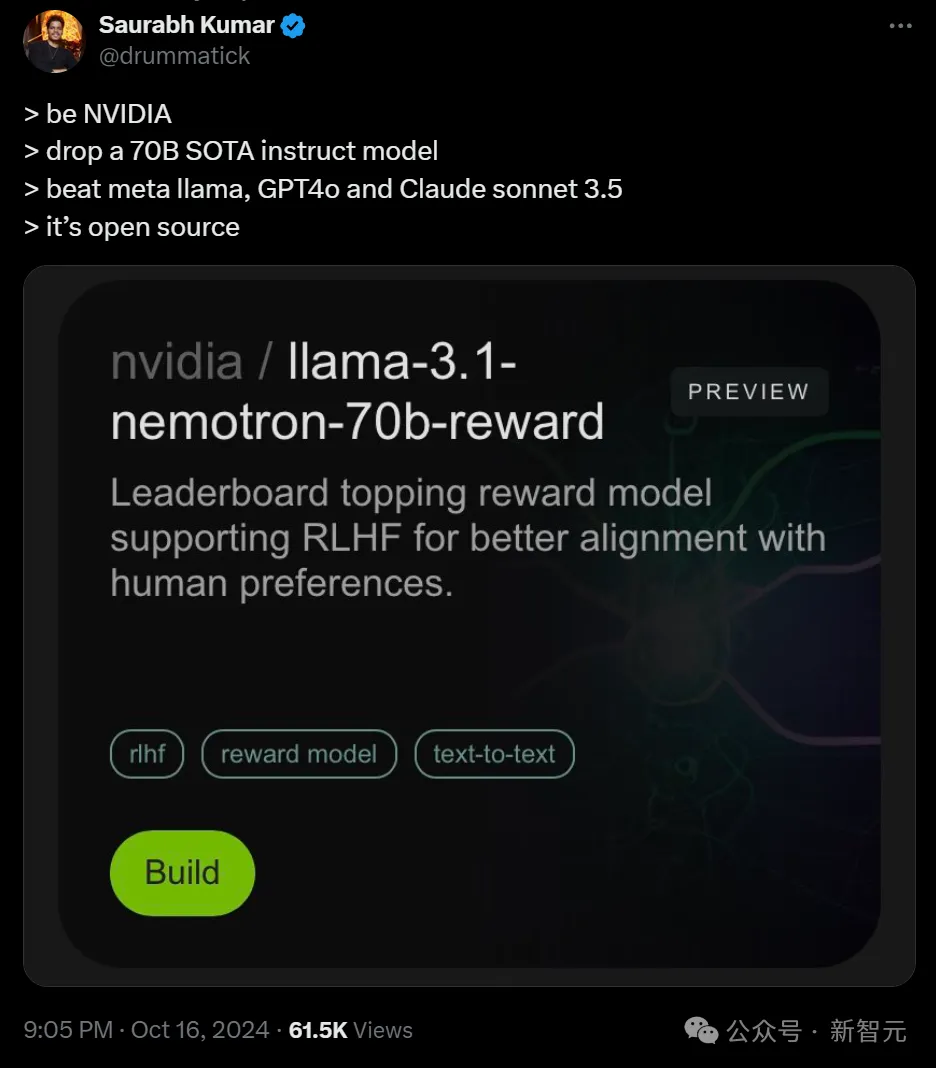
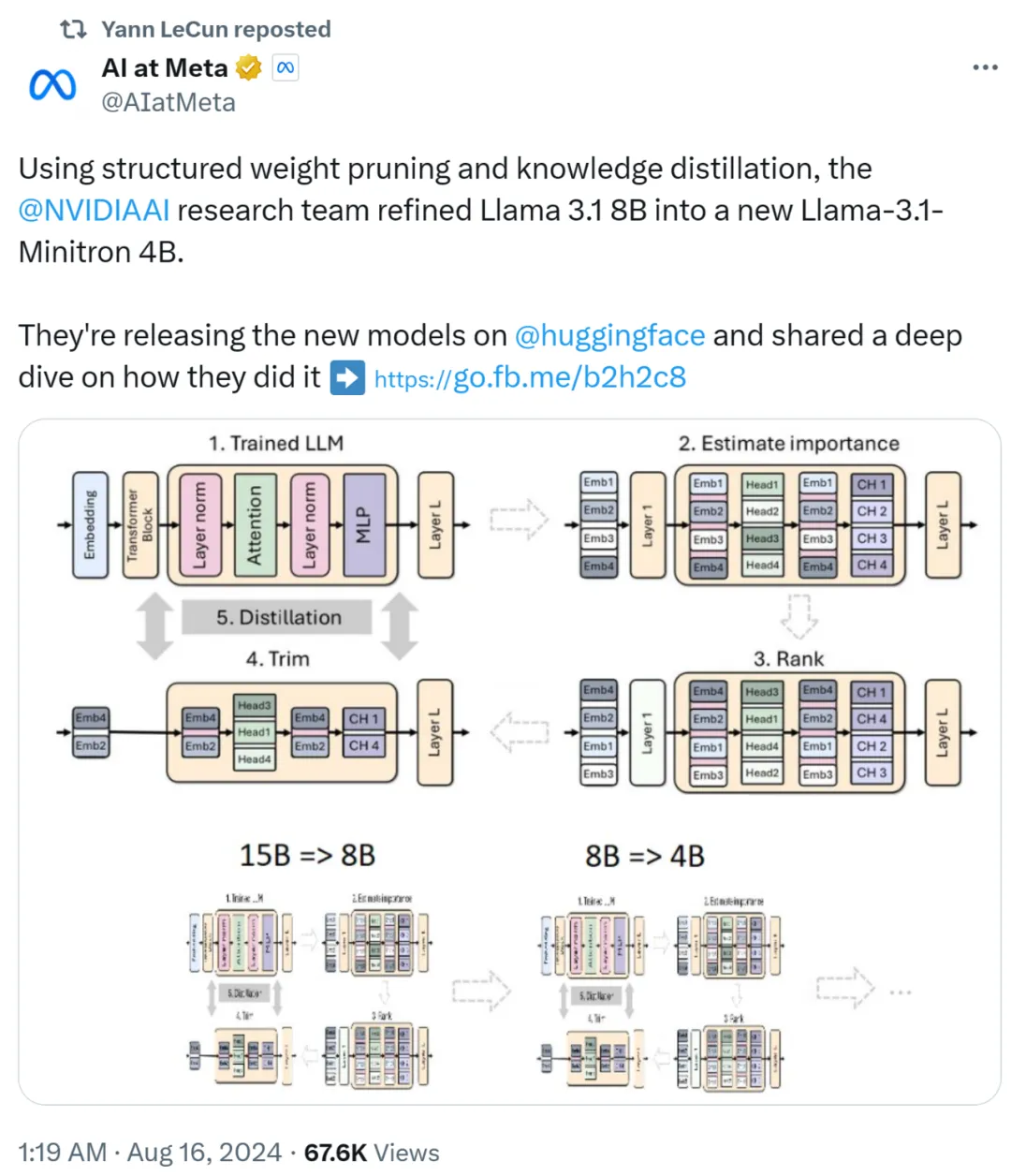
英伟达开源了超强模型Nemotron-70B,后者一经发布就超越了GPT-4o和Claude 3.5 Sonnet,仅次于OpenAI o1!AI社区惊呼:新的开源王者又来了?业内直呼:用Llama 3.1训出小模型吊打GPT-4o,简直是神来之笔!

随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。
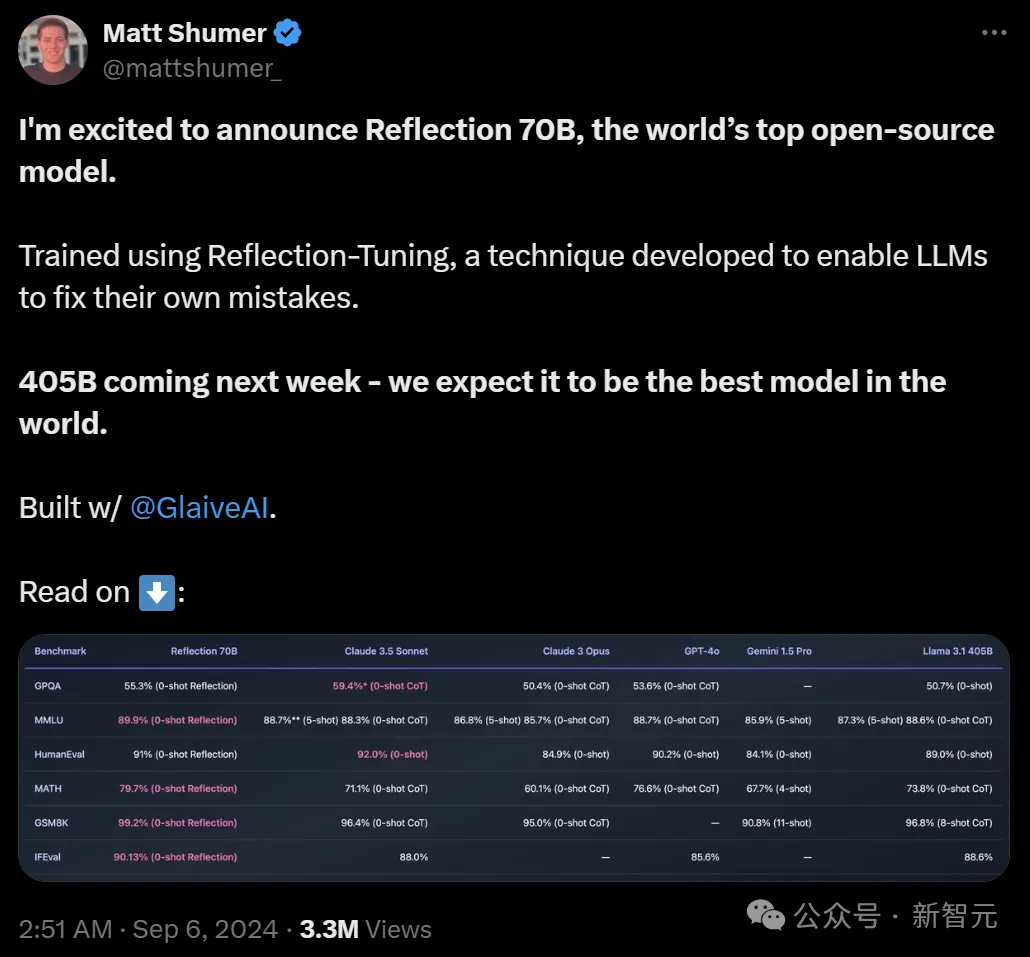
「开源新王」Reflection 70B,才发布一个月就跌落神坛了? 9月5日,Hyperwrite AI联创兼CEO Matt Shumer在X上扔出一则爆炸性消息—— 用Meta的开源Llama 3.1-70B,团队微调出了Reflection 70B。

如果可以使用世界上所有的算力来训练AI模型,会怎么样?近日,凭借发布了开源的Hermes 3(基于Llama 3.1)而引起广泛关注的Nous Research,再次宣布了一项重大突破——DisTrO(分布式互联网训练)。
快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。

最近,Meta的多个工程团队联合发表了一篇论文,描述了在引入基于GPU的分布式训练时,他们如何为其「量身定制」专用的数据中心网络。

随着LLM不断迭代,偏好和评估数据中大量的人工标注逐渐成为模型扩展的显著障碍之一。Meta FAIR的团队最近提出了一种使用迭代式方法「自学成才」的评估模型训练方法,让70B参数的Llama-3-Instruct模型分数超过了Llama 3.1-405B。
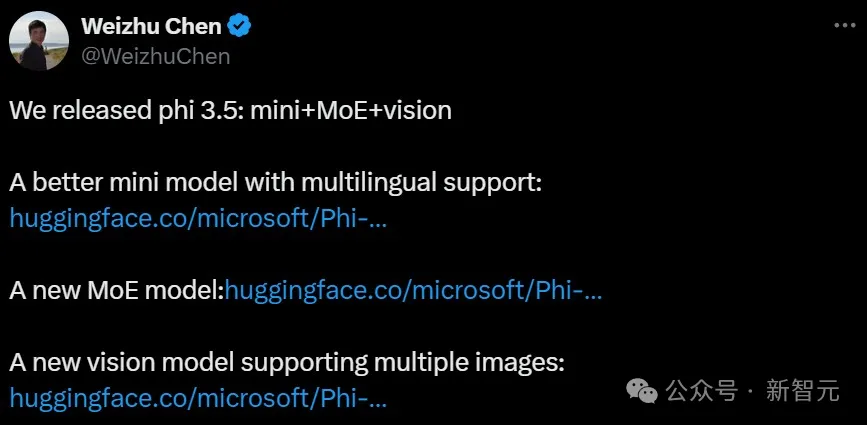
微软Phi 3.5系列上新了!mini模型小而更美,MoE模型首次亮相,vision模型专注多模态。
小模型崛起了。